Data Cleaning and Feature Engineering
Contents
Data Cleaning and Feature Engineering
We now turn to data cleaning and feature engineering for use in neural network for detecting bots. As we searched the literature on how to approach this problem, we learned that feature engineering was key to developing a good set of predictors that helps improve the accuracy of the model. We took advice from the work done with Botometer, a network used for detection of bots created by Indiana University (https://botometer.iuni.iu.edu/#!/). As seen in the image below, obtained from Botometer’s literature, they created over 1000 features for use in their network. We were not so ambitious as this is mostly for learning purposes, but we gathered that feature engineering was important for this work to produce good results.


We proceeded to continue to clean data as we learned more about its structure and generated features as we progressed through the data.
We noticed that some columns contained no information at all. This next section of code checks for columns that contain no information and drops these columns from the dataframe.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
empty_cols = []
for c in df.select_dtypes(include=numerics).columns:
if len(np.isnan(df[c].unique()))==1 & np.isnan(df[c].unique())[0]:
empty_cols.append(c)
df = df.drop(empty_cols, axis=1)
print('The following columns only contained nulls: {0}, these have been dropped'.format(empty_cols))
Output:
The following columns only contained nulls: ['favorited', 'geo', 'retweeted'], these have been dropped
A description of data results in the following table:
| favorite_count | num_hashtags | num_mentions | num_urls | possibly_sensitive | reply_count | retweet_count | truncated | bots | |
|---|---|---|---|---|---|---|---|---|---|
| count | 6.637615e+06 | 6.637615e+06 | 6.637615e+06 | 6.637615e+06 | 26812.0 | 6.637615e+06 | 6.637615e+06 | 753.0 | 6.637616e+06 |
| mean | 2.352860e+00 | 1.561749e-01 | 3.908975e-01 | 2.003855e-01 | 1.0 | 2.848357e-02 | 3.832842e+02 | 1.0 | 5.722317e-01 |
| std | 3.313966e+02 | 5.913658e-01 | 7.311432e-01 | 4.062391e-01 | 0.0 | 1.474201e+01 | 1.100351e+04 | 0.0 | 4.947551e-01 |
| min | -1.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 |
| 25% | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 |
| 50% | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 | 0.000000e+00 | 1.0 | 1.000000e+00 |
| 75% | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 | 0.000000e+00 | 1.0 | 0.000000e+00 | 0.000000e+00 | 1.0 | 1.000000e+00 |
| max | 1.353000e+05 | 2.800000e+01 | 1.900000e+01 | 6.000000e+00 | 1.0 | 2.751600e+04 | 3.350111e+06 | 1.0 | 1.000000e+00 |
we noticed from the describe command above that some columns have very few observations (‘possibly_sensitive’ and ‘truncated’). Reading Twitter’s API pages about these two variables, we determined that it was safe to drop these variables for analysis as 1) they have too few observations, and 2) the values are not very useful as they are proxies of other variables.
See https://developer.twitter.com/en/docs/tweets/data-dictionary/overview/tweet-object.html for information about variables
We then look at the data a bit:
| contributors | crawled_at | created_at | favorite_count | id | in_reply_to_screen_name | in_reply_to_status_id | in_reply_to_user_id | num_hashtags | num_mentions | ... | place | reply_count | retweet_count | retweeted_status_id | source | text | timestamp | updated | user_id | bots | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 2015-05-01 12:57:19 | Fri May 01 00:18:11 +0000 2015 | 0.0 | 593932392663912449 | NaN | 0 | 0 | 0.0 | 1.0 | ... | NaN | 0.0 | 1.0 | 593932168524533760 | <a href="http://tapbots.com/tweetbot" rel="nof... | RT @morningJewshow: Speaking about Jews and co... | 2015-05-01 02:18:11 | 2015-05-01 12:57:19 | 678033 | 0.0 |
| 1 | NaN | 2015-05-01 12:57:19 | Thu Apr 30 21:50:52 +0000 2015 | 0.0 | 593895316719423488 | NaN | 0 | 0 | 0.0 | 0.0 | ... | NaN | 0.0 | 0.0 | 0 | <a href="http://twitter.com" rel="nofollow">Tw... | This age/face recognition thing..no reason pla... | 2015-04-30 23:50:52 | 2015-05-01 12:57:19 | 678033 | 0.0 |
| 2 | NaN | 2015-05-01 12:57:19 | Thu Apr 30 20:52:32 +0000 2015 | 0.0 | 593880638069018624 | NaN | 0 | 0 | 2.0 | 0.0 | ... | NaN | 0.0 | 0.0 | 0 | <a href="http://twitter.com" rel="nofollow">Tw... | Only upside of the moment I can think of is th... | 2015-04-30 22:52:32 | 2015-05-01 12:57:19 | 678033 | 0.0 |
| 3 | NaN | 2015-05-01 12:57:19 | Thu Apr 30 18:42:40 +0000 2015 | 1.0 | 593847955536252928 | NaN | 0 | 0 | 2.0 | 0.0 | ... | NaN | 0.0 | 2.0 | 0 | <a href="http://tapbots.com/tweetbot" rel="nof... | If you're going to think about+create experien... | 2015-04-30 20:42:40 | 2015-05-01 12:57:19 | 678033 | 0.0 |
| 4 | NaN | 2015-05-01 12:57:19 | Thu Apr 30 18:41:36 +0000 2015 | 0.0 | 593847687847350272 | NaN | 0 | 0 | 0.0 | 0.0 | ... | NaN | 0.0 | 0.0 | 0 | <a href="http://tapbots.com/tweetbot" rel="nof... | Watching a thread on FB about possible future ... | 2015-04-30 20:41:36 | 2015-05-01 12:57:19 | 678033 | 0.0 |
5 rows × 21 columns
We also noticed that columns ‘contributors’, ‘in_reply_to_screen_name’, and ‘place’ appear to have lots of NaNs, we looked at the columns to see if they contained useful information:
for c in ['contributors', 'in_reply_to_screen_name', 'place']:
print('column {:s} has {:d} unique values:'.format(c, len(df[c].unique())))
print(df[c].unique())
print()
Output:
column contributors has 1 unique values:
[nan]
column in_reply_to_screen_name has 271336 unique values:
[nan 'thelancearthur' 'wkamaubell' ... 'QueenBitchEnt' 'QBLilKim'
'TokyozFinest1']
column place has 3191 unique values:
[nan 'Tucson, AZ' 'Casas Adobes, AZ' ... 'Cártama, Malaga'
'Chalco, Messico' 'Universiti Multimedia, Bukit Baru']
The ‘contributors’ column is empty so we removed it. The other two columns did contain information about tweets and we decided to keep them.
Checking for Null Values
We check if some columns that should contain a numerical value contain any Null values.
for c in df.columns:
if df[c].isna().sum() > 0:
print('column {:s} has {:d} null values'.format(c, df[c].isna().sum()))
Output:
column crawled_at has 196028 null values
column created_at has 1 null values
column favorite_count has 1 null values
column in_reply_to_screen_name has 5598482 null values
column in_reply_to_status_id has 1 null values
column in_reply_to_user_id has 1 null values
column num_hashtags has 1 null values
column num_mentions has 1 null values
column num_urls has 1 null values
column place has 6508965 null values
column reply_count has 1 null values
column retweet_count has 1 null values
column retweeted_status_id has 196028 null values
column source has 73 null values
column text has 13007 null values
column timestamp has 1 null values
column updated has 196028 null values
column user_id has 1 null values
We noticed a few things here: There are several columns with only 1 null value, and some columns with many null values. We explored further to determine if we could fill this missing data or if we could drop them.
We first checked all columns that contain only 1 null, maybe they all point the the exact same observation. if this is the case, then we could simply delete this observation and we would only loose a single data point.
single_nulls = ['created_at', 'favorite_count', 'in_reply_to_status_id',
'in_reply_to_user_id', 'num_hashtags', 'num_mentions',
'num_urls', 'reply_count', 'retweet_count', 'timestamp', 'user_id']
for c in single_nulls:
print('index {:d} is where the null is for column {:s}'.format(df.loc[df[c].isna()].index[0],c))
Output:
index 2839361 is where the null is for column created_at
index 2839361 is where the null is for column favorite_count
index 2839361 is where the null is for column in_reply_to_status_id
index 2839361 is where the null is for column in_reply_to_user_id
index 2839361 is where the null is for column num_hashtags
index 2839361 is where the null is for column num_mentions
index 2839361 is where the null is for column num_urls
index 2839361 is where the null is for column reply_count
index 2839361 is where the null is for column retweet_count
index 2839361 is where the null is for column timestamp
index 2839361 is where the null is for column user_id
As expected, they all correspond to same observation, so we deleted this observation.
columns ‘crawled_at’ and ‘updated’ were columns added by the researchers. They used twitter crawlers to collect information for this database. These columns do not belong to information about users that can be collected through Twitter’s API, hence we decided to drop these two columns as well.
for c in df.columns:
if df[c].isna().sum() > 0:
print('column {:s} has {:d} null values'.format(c, df[c].isna().sum()))
Output:
column in_reply_to_screen_name has 5598481 null values
column place has 6508964 null values
column retweeted_status_id has 196027 null values
column source has 72 null values
column text has 13006 null values
the varaibles ‘in_reply_to_screen_name’ and ‘place have’ large amounts of null values. When looking at Twitter’s API description of these variables, we foudn that these values are null if:
for in_reply_to_screen_name if the tweet is not a reply
for place, if the tweet has no location data
This presented an interesting opportunity. We looked at what percentage of tweets that have either ‘place’ data or ‘in_reply_to_screen_name’ data correspond to genuine accounts.
df.loc[df.in_reply_to_screen_name.isna()==False].bots.sum()/len(df.loc[df.in_reply_to_screen_name.isna()==False])
Output:
0.20234637688690776
df.loc[df.place.isna()==False].bots.sum()/len(df.loc[df.place.isna()==False])
Output:
0.05719349247188129
These are interesting results. Of the tweets that are replies, only 20% come from bots. And of the tweets that have location data, only 5% come from bots.
Since the actual value of ‘in_reply_to_screen_name’ and ‘place’ variable is not very important as they have small sample sizes, we created a binary variable for each to indicate if a tweet is a reply, and if a tweet has place data. This might prove to be more useful than the actual value it currently holds. We dropped the original columns.
reply = np.zeros(len(df))
idx = df.loc[df.in_reply_to_screen_name.isna()==False].index
np.put(reply, idx, 1)
location_data = np.zeros(len(df))
idx = df.loc[df.place.isna()==False].index
np.put(location_data, idx, 1)
df['reply'] = reply
df['location_data'] = location_data
df = df.drop(['place','in_reply_to_screen_name', 'in_reply_to_status_id', 'in_reply_to_user_id', 'id'], axis=1)
Text feature, which corresponds to the text of the tweet also presents some missing data. We left this untouched for now. But we created a feature that counts the number of words in a tweet. Those tweets without text will be assumed to have 0 number of words.
num_words = []
for i, s in enumerate(df.text):
try:
num_words.append(len(s.split()))
except AttributeError:
num_words.append(0)
df['num_words'] = num_words
We searched information on what ‘retweeted_status_id’ represents and we did not find any good information on it. There is a variable on Twitter called ‘retweeted_status’, but it differs in data format from the one we have. Our guess is that the variable we have represents the id of the user for which the twitter is being retweeted. Since we were not going to acquiring additional data outside the dataset we received from the researchers, we decided to drop this column.
for c in df.columns:
if df[c].isna().sum() > 0:
print('column {:s} has {:d} null values'.format(c, df[c].isna().sum()))
Output:
column source has 72 null values
column text has 13006 null values
The ‘source’ column represents information related to the infrastructure/platform where the tweet came from. For example, if it was typed through twitter online, it will say so, if it was typed through twitter on a phone, it will say something like “twitter for android” or “twitter for ios”, etc.
This is likely to prove to be an important feature. We filled the 72 missing values with the most common value as it is only 72 observations (tiny when compared to the number of total observations). Then, then categorized the sources from most common to least common into 10 categories and one-hot-encoded them.
source = df.source.str.extract(r'>\s*([^\.]*)\s*\<', expand=False)
source_counts = source.value_counts()
df = df.fillna({'source':source_counts.index[0]}, axis=0)
We looked at the distribution of ‘source’ to see how we can categorize them:
source_norm = (source_counts-source_counts.min())/(source_counts.max()-source_counts.min())
fig, ax = plt.subplots(figsize=(9,6))
threshold = 0.02
mask = source_norm > threshold
tail_prob = source_norm.loc[~mask].sum()
prob = source_norm.loc[mask]
prob['other'] = tail_prob
prob.plot(kind='bar')
plt.show()
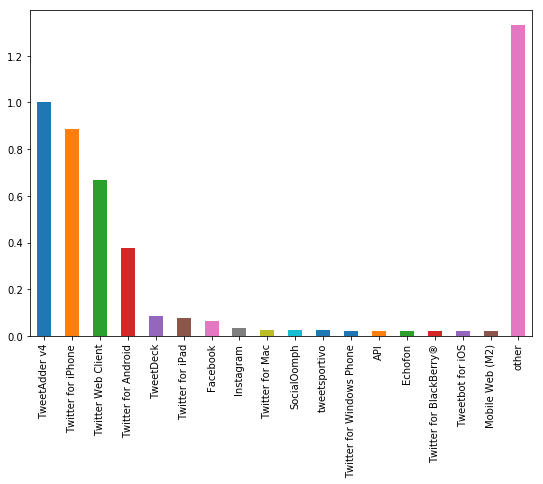
We can observe from the above distribution that the most common values are ‘TweetAdder v4’, ‘Twitter for iPhone’, ‘Twitter Web Client’, and ‘Twitter for Android’. We decided to split the data into 10 bins corresponding to the top 9 sources and then a single category for all the rest.
l = list(source_counts.index[0:9])
source_new = []
for s in source:
if s in l:
source_new.append(s)
else:
source_new.append('other')
df['source'] = source_new
df = pd.get_dummies(df, columns=['source'])
It was important to manage the timestamp of tweets and engineer some features from this variable. We focused on extracting the year, month, day, hour, minutes and second in which a tweet was made; also for each unique user, how often they tweet. (This process took about 24 mintues to run).
df.created_at = pd.to_datetime(df.created_at, errors='coerce')
pd.isnull(df.created_at).sum()
Output:
145094
We have about 145,000 observations that don’t contain data of when the tweet was created. We will delete these observations as we still have millions of observations to use in the model. We then created date features and stored them in a clean csv for later use.
df['year'] = df.created_at.dt.year
df['month'] = df.created_at.dt.month
df['day'] = df.created_at.dt.day
df['hour'] = df.created_at.dt.hour
df['minute'] = df.created_at.dt.minute
df['second'] = df.created_at.dt.second
df.to_csv('data/clean_tweets.csv')
Cleaning User Data
We first read the data for users from the first file to create a dataframe:
df_users = pd.read_csv("data/datasets_full/genuine_accounts/users.csv")
df_users["bots"] = 0
df_users.head()
| bots | contributors_enabled | crawled_at | created_at | default_profile | default_profile_image | description | favourites_count | follow_request_sent | followers_count | ... | profile_use_background_image | protected | screen_name | statuses_count | time_zone | timestamp | updated | url | utc_offset | verified | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | NaN | 2015-05-02 06:41:46 | Tue Jun 11 11:20:35 +0000 2013 | NaN | NaN | 15years ago X.Lines24 | 265 | NaN | 208 | ... | NaN | NaN | 0918Bask | 2177 | NaN | 2013-06-11 13:20:35 | 2016-03-15 15:53:47 | NaN | NaN | NaN |
| 1 | 0 | NaN | 2015-05-01 17:20:27 | Tue May 13 10:37:57 +0000 2014 | 1.0 | NaN | 保守見習い地元大好き人間。 経済学、電工、仏教を勉強中、ちなDeではいかんのか? (*^◯^*) | 3972 | NaN | 330 | ... | 1.0 | NaN | 1120Roll | 2660 | Tokyo | 2014-05-13 12:37:57 | 2016-03-15 15:53:48 | NaN | 32400.0 | NaN |
| 2 | 0 | NaN | 2015-05-01 18:48:28 | Wed May 04 23:30:37 +0000 2011 | NaN | NaN | Let me see what your best move is! | 1185 | NaN | 166 | ... | 1.0 | NaN | 14KBBrown | 1254 | Eastern Time (US & Canada) | 2011-05-05 01:30:37 | 2016-03-15 15:53:48 | NaN | -14400.0 | NaN |
| 3 | 0 | NaN | 2015-05-01 13:55:16 | Fri Sep 17 14:02:10 +0000 2010 | NaN | NaN | 20. menna: #farida #nyc and the 80s actually y... | 60304 | NaN | 2248 | ... | 1.0 | NaN | wadespeters | 202968 | Greenland | 2010-09-17 16:02:10 | 2016-03-15 15:53:48 | http://t.co/rGV0HIJGsu | -7200.0 | NaN |
| 4 | 0 | NaN | 2015-05-02 01:17:32 | Fri Feb 06 04:10:49 +0000 2015 | 1.0 | NaN | Cosmetologist | 5 | NaN | 21 | ... | 1.0 | NaN | 191a5bd05da04dc | 82 | NaN | 2015-02-06 05:10:49 | 2016-03-15 15:53:48 | NaN | NaN | NaN |
5 rows × 41 columns
We kept the variables that might have explanatory power, and/or have enough information that would be useful for our models. Many of the excluded variables did not have enough information to be useful (mostly NaNs). Others did not seem contribute at all for identifying fake tweets, for example the date in which the account was created (although we found useful the informatoin on the date in which the tweets are created, and we kept the latter). And we save the clean data in a csv file.
users_features_to_keep = ["favourites_count", "followers_count", "friends_count", "id", "listed_count", "statuses_count", "bots"]
df_users_clean = df_users[users_features_to_keep]
df_users_clean.rename(columns={'id': 'user_id'}, inplace=True)
df_users_clean.to_csv("data/clean_users.csv", index=False)